Abstract
Vision-and-Language Navigation requires the agent to follow language instructions to navigate through 3D environments. One main challenge in Vision-and-Language Navigation is the limited availability of photorealistic training environments, which makes it hard to generalize to new and unseen environments. To address this problem, we propose PanoGen, a generation method that can potentially create an infinite number of diverse panoramic environments conditioned on text. Specifically, we collect room descriptions by captioning the room images in existing Matterport3D environments, and leverage a state-of-the-art text-to-image diffusion model to generate the new panoramic environments. We use recursive outpainting over the generated images to create consistent 360-degree panorama views. Our new panoramic environments share similar semantic information with the original environments by conditioning on text descriptions, which ensures the co-occurrence of objects in the panorama follows human intuition, and creates enough diversity in room appearance and layout with image outpainting. Lastly, we explore two ways of utilizing PanoGen in VLN pre-training and fine-tuning. We generate instructions for paths in our PanoGen environments with a speaker built on a pre-trained vision-and-language model for VLN pre-training, and augment the visual observation with our panoramic environments during agents' fine-tuning to avoid overfitting to seen environments. Empirically, learning with our PanoGen environments achieves the new state-of-the-art on the Room-to-Room, Room-for-Room, and CVDN datasets. Besides, we find that pre-training with our PanoGen speaker data is especially effective for CVDN, which has under-specified instructions and needs commonsense knowledge to reach the target. Lastly, we show that the agent can benefit from training with more generated panoramic environments, suggesting promising results for scaling up the PanoGen environments to enhance agents' generalization to unseen environments.
Overview
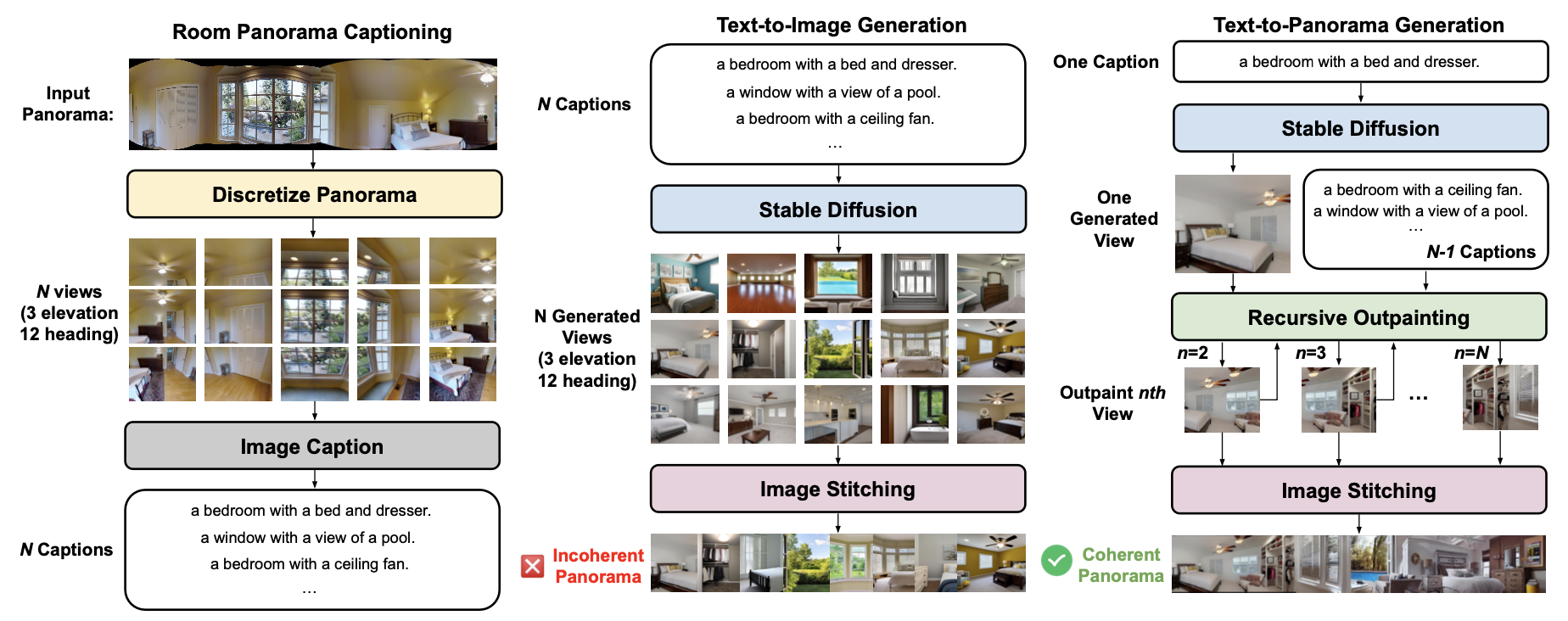
Overview of our PanoGen. We first generate captions for all the room panoramas in the Matterport3D dataset. Each panorama is discretized into 36 views, we show 15 views here for a better view of each discretized image. Then, we generate panoramic environments with recursive outpainting over a single image generated from the text caption.
Method
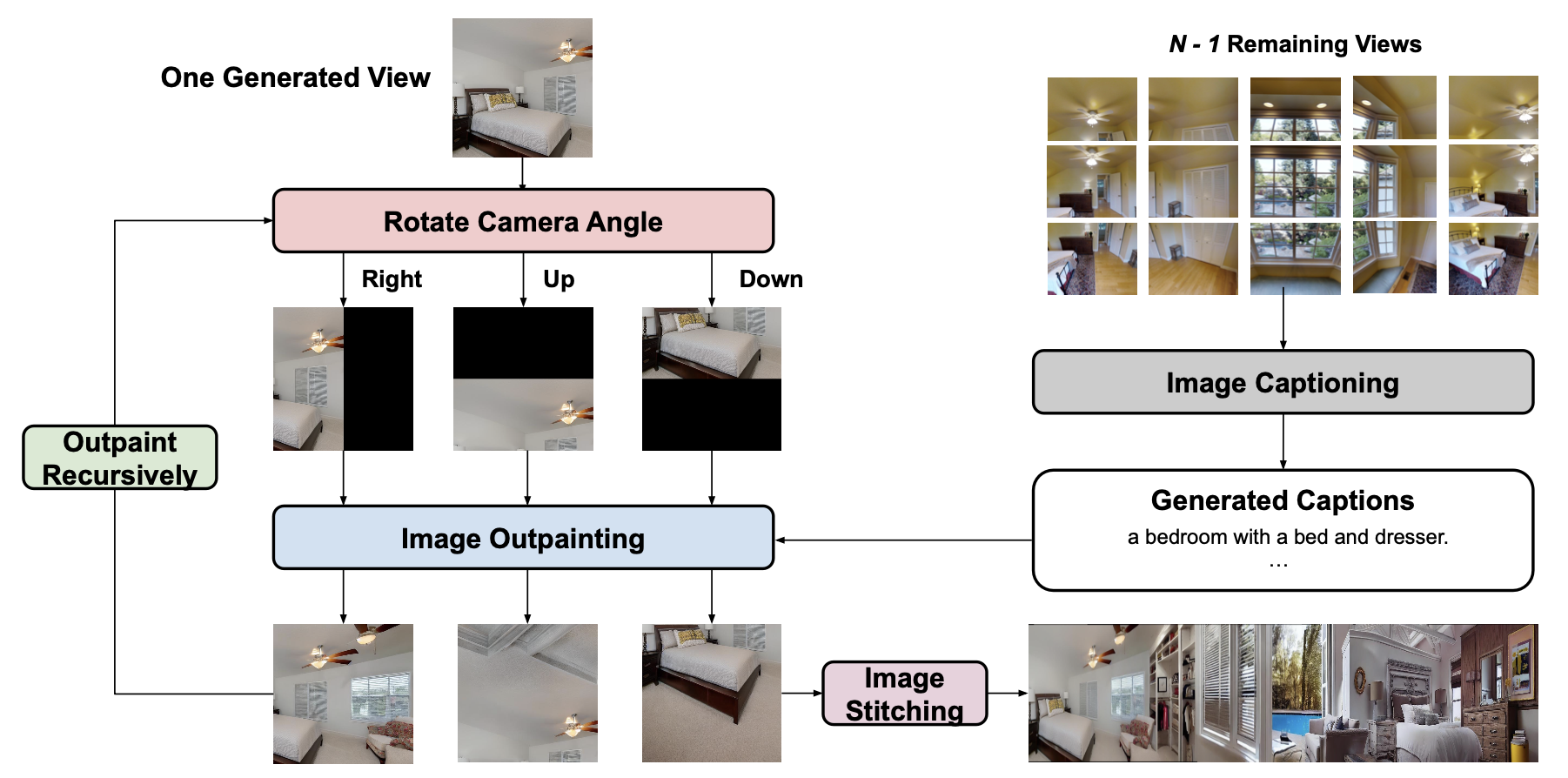
We first collect descriptions of room environments by using a state-of-the-art vision-language model BLIP-2 to annotate the view images in the Matterport3D dataset. Then, we use text-to-image diffusion models to generate diverse room images based on the text captions. Specifically, we propose a `recursive' image outpainting approach, which reconstructs missing regions in an image based on text captions. We choose one generated image in the panorama as the starting point, and gradually rotate the camera angle right, left, up, and down, and then outpaint the unseen observation based on text descriptions.
Generation Examples

Directly generating discretized views based on caption will be disjoint and inconsistent (Row “Stable Diffusion for Discretized Views”). In comparison, our recursive outpainting approach could generate continuous views that can be stitched together to form a high-quality panorama (Row “PanoGen”). Besides the high quality and coherency, our generated panorama environments is able to preserve the wide range of objects appeared in the original environments, while generating them with new appearance and different room layout. For example, in the left generated panorama, it contains a corridor view, and shows multiple rooms that are connected to the corridor (e.g., bedroom, and bathroom). This layout also follows human's commonsense knowledge, where the bedroom and bathroom can be connected with a corridor.
Results
Test Leaderboard Performance
| Model | R2R | CVDN | ||||
|---|---|---|---|---|---|---|
| Val Unseen | Test | Val Unseen | Test | |||
| SR | SPL | SR | SPL | GP | GP | |
| PREVALENT | 58 | 53 | 54 | 51 | 3.15 | 2.44 |
| Rec-BERT | 63 | 57 | 63 | 57 | - | - |
| HAMT | 66 | 61 | 65 | 60 | 5.13 | 5.58 |
| DUET | 72 | 60 | 69 | 59 | - | - |
| PanoGen | 74 | 64 | 72 | 62 | 5.93 | 7.17 |
Comparison with state-of-the-art agents on Room-to-Room (R2R) and Cooperative Vision-and-Dialog Navigation (CVDN) validation unseen set and test leaderboard.
Ablation Results -- Effectiveness of Speaker Data

Ablation Results -- Effectiveness of Observation Augmentation

BibTeX
@article{li2023panogen,
author = {Jialu Li, and Mohit Bansal},
title = {PanoGen: Text-Conditioned Panoramic Environment Generation for Vision-and-Language Navigation},
journal = {arxiv},
year = {2023},
}